-
Exercise 1: Explain under which assumptions the fail-recovery and the fail-silent models are similar in (note that in both models any process can commit omission faults).
-
Exercise 2: Show how to make a stubborn point-to-point link by calling an instance of a fair-loss link API.
-
Exercise 3: Describe the implementation of a perfect failure detector for a synchronous system
-
Exercise 4: Does the following statement satisfy the synchronous-computation assumption? On my server, no request ever takes more than 1 week to be processed.
-
Exercise 5: Is it possible to design a perfect failure detector for byzantine faults?
Same principle as not being able to make an perfect falior detector for an an asyncronous system.
-
Exercise 6: Assume you have provided a cloud application alone, and aim to provide an SLA for potential customers. Would you offer 90%, 99%, or 99.9% uptime per month to the customer? If you give a 99% per month SLA, how many crashes of your application do you expect to have to deal with in a month, and how quickly do you think this can be dealt with? Provide a detailed calculation of how many minutes of downtime each option allows you to fix issues. 90% = = 36 days 99% = = 3.6 days 99,9% = = 8 hours
-
Exercise 7 MS Azure SLA for VMs: https://www.azure.cn/en-us/support/sla/virtual-machines/ How much time do they get to fix an issue on their side for each SLA listed there? How do you think they expect to achieve such high numbers. What do you think is their sampling frequency (must search for this online)? 99,99% = = 0,9 hours 99,95% = = 4,3 hours 99,9% = = 9 hours 99,5% = = 44 hours 95% = = hours
-
Exercise 8 Consider a network as seen here: In this network, what (minimum) present of messages of node 1 to node 2 go through node 6?
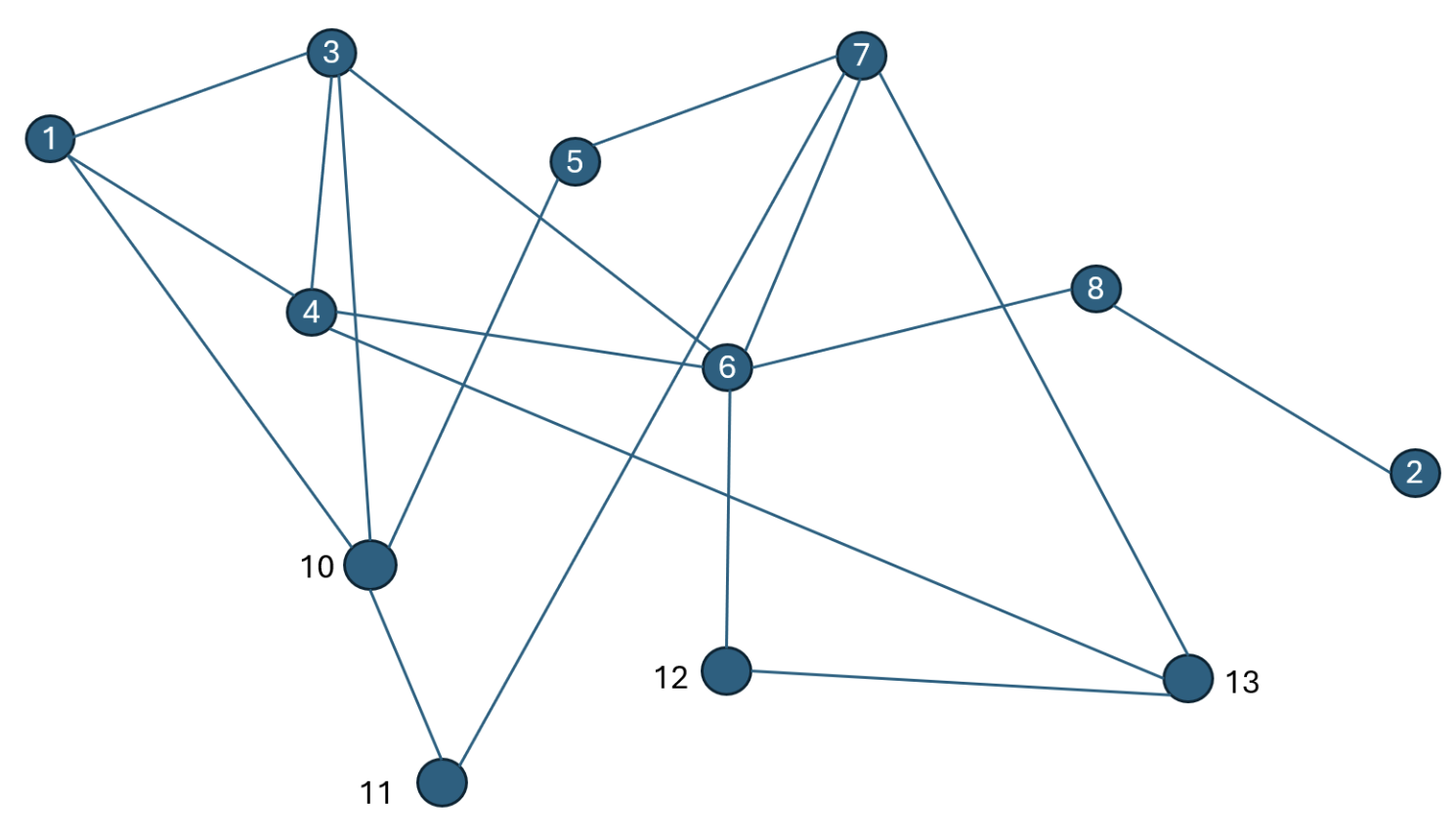
All of them
- Exercise 8.1: Which links would you add so that this network can tolerate any two node crashes without getting any partitions?
2 and 8 need to be connected to the rest of the network, 11, 12, and 5 need an extra connection